
日期:2021年5月11日
本文是關於如何使性能測試無縫地融入持續性能測試和自動化管道的多部分係列文章的第二部分。
第1部分:使用Jenkins管道和Kubernetes進行連續負載測試
第2部分:連續性能測試中的3個殺手級反模式
第3部分:利用趨勢和開放API數據加速性能分析
第1部分的主要要點:
- 使用SCM(例如Git)存儲所有的資產:代碼、測試工件、管道、配置等。
- 開發通用的分支/標簽策略,在所有資產中保持一致
- 在開始調試CI測試/重新配置之前進行分支,然後合並回來
在Tricentis NeoLoad在美國,我們與世界各地的許多不同團隊合作。在軟件開發生命周期中,並不是每個公司都以相同的容量水平或時間間隔實現性能工程實踐。沒關係。在對你的敏捷、DevOps或其他泛濫的軟件森林之旅做出決定時,要記住的一件重要的事情是“哪些差距會阻止我們在已經決定的必須要做的事情之外繼續前進?”
許多人已經決定在整個生命周期(包括性能工程和測試)構建可持續的自動化和連續的流程是現代的當務之急。
避免“為了減速而加速”綜合症
我們浪費時間的原因有一百萬個。“返工”並不是你的價值流中的唯一類別,甚至不是。敏捷和迭代產品團隊經常構建原型來了解問題並生成可用的產品。雖然我們都可以改進計劃和需求收集,但我們經常發現自己由於未預料到的依賴關係和不一致的期望而無法關閉工作項。
在性能測試在開始之前,必須準備好許多東西:非功能需求/標準、測試環境、係統/服務規範、跨產品、開發和運營團隊一致的服務水平目標(slo)的清晰定義、測試數據等等。這些是通常的懷疑,但是當您開始在持續交付過程中實現性能測試時,這有什麼不同呢?
從我們與客戶和合作夥伴團隊的所有經驗中,我們總結出了一些重要的經驗教訓,以確保您的旅程不會從關鍵的障礙開始:
- 測試存儲、分支和版本控製應該匹配開發和操作模式和周期(例如,特性工作、衝刺強化階段等)。
- 在持續集成和編排平台中使用的發布就緒分支的衝刺期間,促進測試工件變更的清晰滑動路徑
- 測試期間的調試問題,並將實際係統缺陷與測試和部署過程問題區分開來
讓我們從第一個攔截器開始——您的測試存儲策略。
開發人員需要一個性能“啞巴按鈕”,這很好
在將性能測試包裝到持續構建過程之前,它需要完全自動化。但是這對於API的負載測試意味著什麼呢?
您的性能測試需要在您的自動化CI作業能夠清晰而快速地訪問的地方。許多組織已經轉向某種形式的遵循git的源代碼管理(SCM)係統:GitLab, AWS CodeCommit, Azure Repos, Bitbucket等。
考慮將性能測試存儲在一個單一的豎井中,如Micro Focus performance Center,將性能工程活動與CI工具(例如Jenkins、TeamCity、Bamboo、Digital)中的現代自動化生命周期(ALM)的其餘部分隔離開來。ai Release, née XebiaLabs XLRelease)。這種方法使性能測試活動成為隻有少數人能夠做的事情。
一些簡化流程鼓勵自治,一些則不然
我們最近會見了一個F20+組織的DevOps/雲工程、可伸縮性和性能團隊,該組織正在剝離所有Micro Focus產品。雖然他們詳細闡述了他們目前的經驗,通過創建部署手冊來為Go、Node.js和基於java的係統提供各種技術堆棧,為他們的應用程序和服務開發團隊提供更大的自主權,但他們有一個很棒的觀點——讓一些事情變得容易,也會讓他們很難學習如何在出現問題時解決問題。
我們很了解這個問題。不了解Docker或Kubernetes的客戶要求使用本地OpenShift集成之類的功能,以便無縫地旋轉負載控製器和生成器。許多自動化的分析過程使用我們的REST api用於測試執行、實時快速故障判定、數據提取和流到可視化工具,如Splunk、Kibana和Prometheus。他們構建這些工具是為了讓開發人員能夠按下Jenkins中的“啞巴按鈕”,並獲得可操作的性能結果。
為不懂cli的人簡化Git語義
這就是為什麼Tricentis NeoLoad提供了與Git源代碼的直接集成,因此每個人都可以在性能測試的細節上進行協作,以與開發源代碼中的特性/衝刺分支相匹配的方式對他們的更改進行版本化,並在任何地方執行它們,所有這些都在幾分鍾而不是幾小時內完成。
NeoLoad中的Git鼓勵各級工程師之間的自治和協作。
對於不熟悉Git命令行界麵(CLI)的貢獻者,NeoLoad桌麵工作台中的Git功能簡化了事情,使其易於克隆、修改、推送到特定分支,並最終與其他主流CI/CD事件合並(並推廣)這些更改。
NeoLoad還支持負載測試的全基於代碼的YAML描述。不管測試構建和維護的方法是什麼,通過工作站上的圖形界麵,或者使用IDE或您選擇的代碼編輯器,NeoLoad通過在周期的早期可視化並就性能預期達成一致,加速了API負載測試和跨團隊的SLO對齊。
現在,讓我們轉向如何處理這些版本和分支的主題——CI中的“測試提升”。
避免在通往生產的路上碰到每個分支
我們希望我們的代碼投入生產,因為這是賺錢的地方。性能測試對於這個過程至關重要,也就是說,因為您不想在用戶麵前發布失敗的糟糕代碼。但是這種測試帶有版本化的工件,必須與您測試的應用程序或服務代碼相匹配。
這些資產應該彼此同步。當多個團隊和特性同時離開時,您如何確保代碼和測試資產的版本是相同的?你是否傾向於像一些供應商所說的那樣“測試所有的東西”?
對此問題的一個普遍實現的答案是使用Git中的短分支來簡化測試和自動化流程定義更改的驗證和驗證。
分支加速測試推廣
盡管基於主幹的開發是被譽為首選的持續交付策略這鼓勵小的、頻繁的更改,值得提交到一致的代碼庫中(這是一個值得讚揚的目標),考慮到分支在從機器上的作品轉移到生產中的語義中扮演著至關重要的角色,即使在這種方法中也是如此。其他代碼集成模型(如Gitflow和基於流的版本控製)也繼承了這個問題,在大多數情況下,可以通過使用持續集成和編排平台從本地機器刪除代碼,並在(通常)密封環境中重新生成端到端組裝、測試、打包、部署、驗證和發布語義來解決這個問題。
對於CI中的性能測試,管道通常是這樣構造的,以便人類或其他進程(例如,其他主管道、JIRA、webhook和聊天機器人)可以自動觸發它們。你構建,讓它們為與應用程序或服務的當前版本匹配的測試套件工作,然後呢?代碼/環境配置更改,測試也必須更改。你已經在工作版本上有了工作管道和測試,你如何驗證軟件的建議版本和新測試也能工作呢?
答案是——將您的新代碼和測試一起版本化,也許在應用程序和測試存儲庫中使用相同名稱的分支,或者可能在這些資產之間使用匹配的Git標記。由於特性工作或基於衝刺的性能測試,您可能會克隆當前的工作測試套件,修改它並運行本地負載測試,然後將其簽入新的分支,並讓管道在預發布環境中的最新版本的服務上運行測試資產的分支。您甚至可以將您的管道代碼與所有這些資產一起版本化,這樣一旦您證明了一切都在工作,各個存儲庫中的這些分支的提升(例如,合並)就會同時發生。
案例研究:《財富》20強SREs構建可伸縮的CI約定
在前麵提到的對話中,我問DevOps工程師他們最痛苦的工作是什麼。他們幾乎一致地告訴我,這是跨多個雲平台建立的模式和慣例。雖然他們還沒有在內部以可伸縮的方式部署容器,但在遷移到Microsoft Azure、現有的Pivotal Cloud Foundry、大量VMware自動化和穀歌雲平台之間,為開發團隊創建劇本和輔助腳本來部署新服務的想法是他們團隊每天麵臨的主要挑戰。
在這種情況下,不同之處在於他們使用TeamCity和最終的CircleCI來自動化這些劇本,本質上允許完全自動化的目標驅動運動,以改進他們整個組織的實踐。他們有Tricentis NeoLoad因為在他們看來,NeoLoad平台是唯一的負載測試和性能解決方案,可以使用這種自動化模型適應現代、傳統和混合應用程序的所有企業方麵。Git支持,通過開放的RESTful api訪問數據,以及隨時隨地運行測試的靈活性,都非常適合他們的需求。
當他們跨越各種雲和容器提供商擴展這些模式時,使用簡單配置切換來控製單元、集成、功能、回歸和性能測試執行的自動化管道允許多個開發團隊在高層次上遵守風險需求。當然,布爾切換需要測試和數據才能完成,因此他們創建了基於約定的存儲庫和目錄結構,SRE團隊期望在每個管道項目中包含這些特定於項目的構件。這使得開發和性能工程師可以使用NeoLoad Git和基於yaml的測試項目一起詳細說明測試語義和目標。
忽略在“主”分支中修複測試問題的衝動
當性能測試失敗時,理解它們失敗的原因不僅對傳統的深入分析過程至關重要,而且對管道中的自動運行/不運行指示器也至關重要。
當團隊不相信這些通過/失敗警告標誌時,問題就來了。
能夠確定您的自動化流程的哪一部分需要修複,這對於保持它們的正常運行至關重要。根據我們的經驗,使用不同版本的管道來診斷問題可以幫助工程師進行故障隔離、糾正、驗證,然後將他們的更改集成到自動化流程的生產版本中。
我們看到持續的性能測試失敗的首要原因是人們沒有認識到測試他們的更改的價值——忽視更新這些管道無意中會使它們看起來不可靠或損壞。
變更前分支;快速驅動到可合並的修複
在您更改測試、自動化/管道代碼或基礎架構描述(Dockerfiles、Kubernetes部署文件、Chef腳本等)之前,請創建一個新的分支。它們便宜,一次性,而且希望是短命的。
然而,這為經典的單片自動化管道帶來了一個問題:您必須為所有CI作業和配置創建“候選”副本嗎?答案是“通常不會。”以Jenkins多分支管道為例,它允許您指向單個回購,但自動維護每個分支的獨立管道。
當還配置了對Pull/Change Requests的支持時,您可以創建工作流,允許測試重新配置和驗證與管道的生產版本分開進行,直到知道最終的修複可以工作並準備好供其他團隊運行。
區分“硬”和“軟”失敗
性能測試包含大量數據,並不是每次失敗都意味著相同的事情。以下是他們失敗的一些主要原因:
- 您的應用程序/服務無法處理負載測試的壓力
- 提供的負載基礎設施不能執行測試
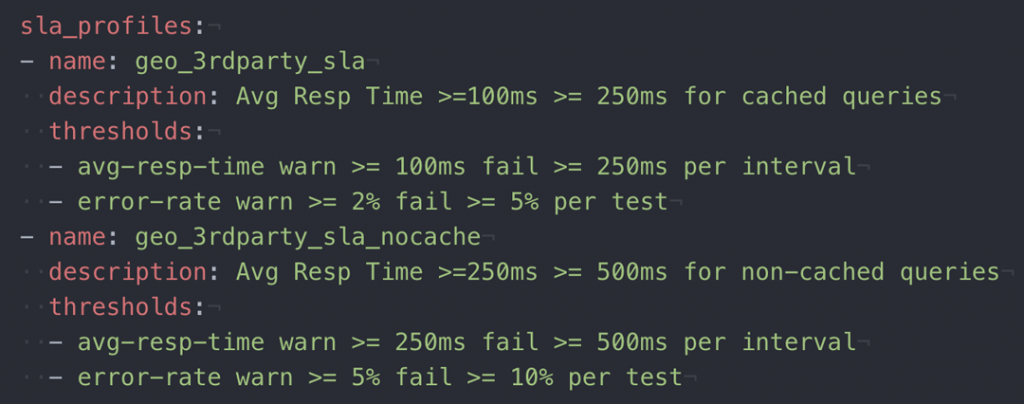
- 違背了一個或多個服務級別目標(有時在工具中稱為sla)
- 負載基礎設施和目標係統之間的網絡或連接故障
- 驗證以證明完整的事務失敗(它們應該失敗)
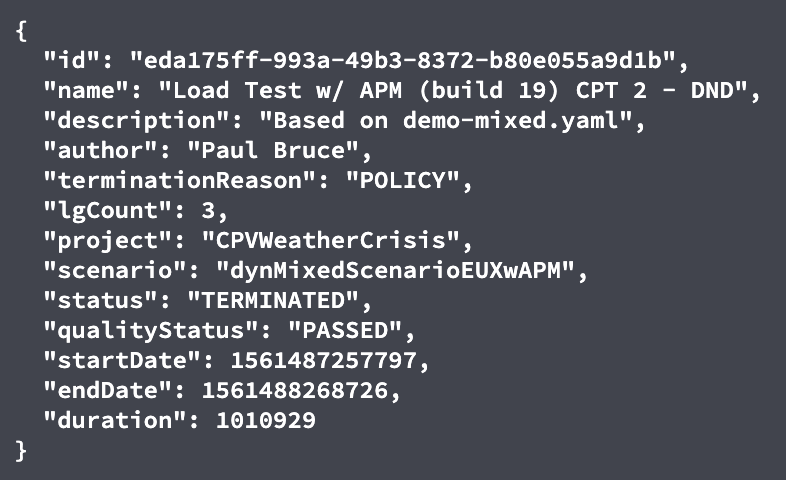
在每種情況下,CI作業使用的高級啟動/不啟動指示器都是必不可少的,但還不足以診斷發生了什麼以及是否需要修複某些東西。例如,流程指示器(如NeoLoad的命令行界麵(CLI)退出碼)提供早期故障級別的詳細信息,以通知管道嚐試/捕獲和編排事件語義。在第一個例子中,測試成功地執行了,但是發生了一些嚴重的SLA違反:
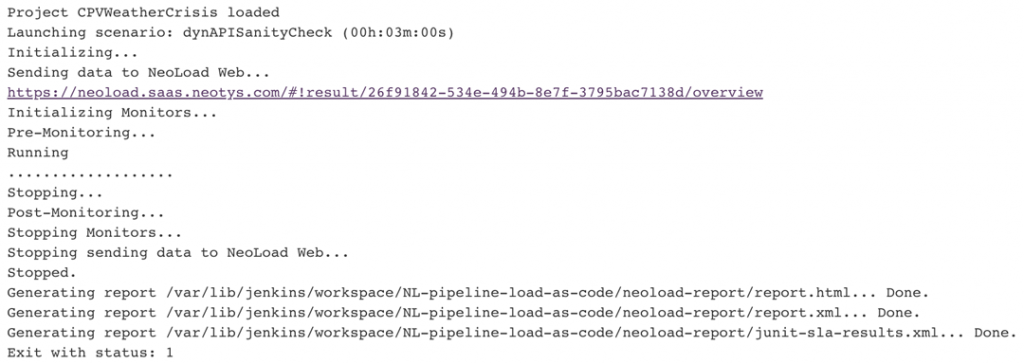

在第二個例子中,由於新的安全約束,我們的負載基礎設施(基於docker的Jenkins構建節點)在連接到Jenkins時出現了一些問題,從而使測試完全無效:
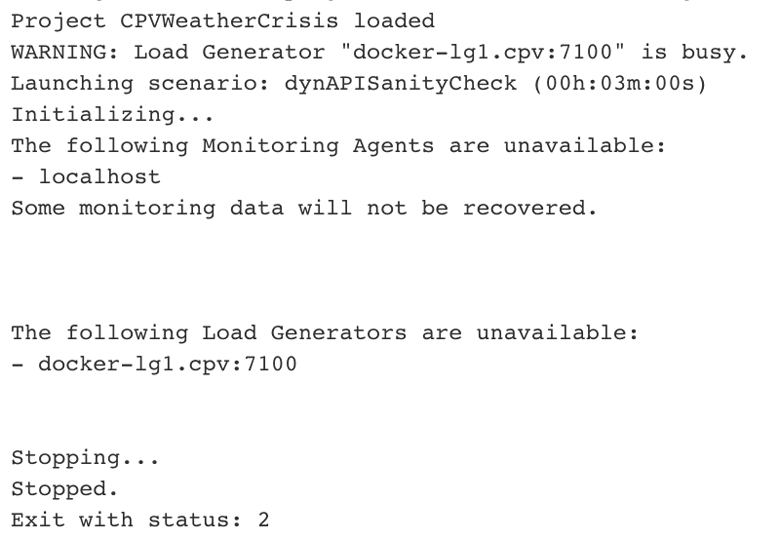
進一步說,NeoLoad API彙總數據可以用來確定成功或失敗的上下文:
此外,可以以類似的方式從不同的API端點檢索特定的SLA數據:
![]()
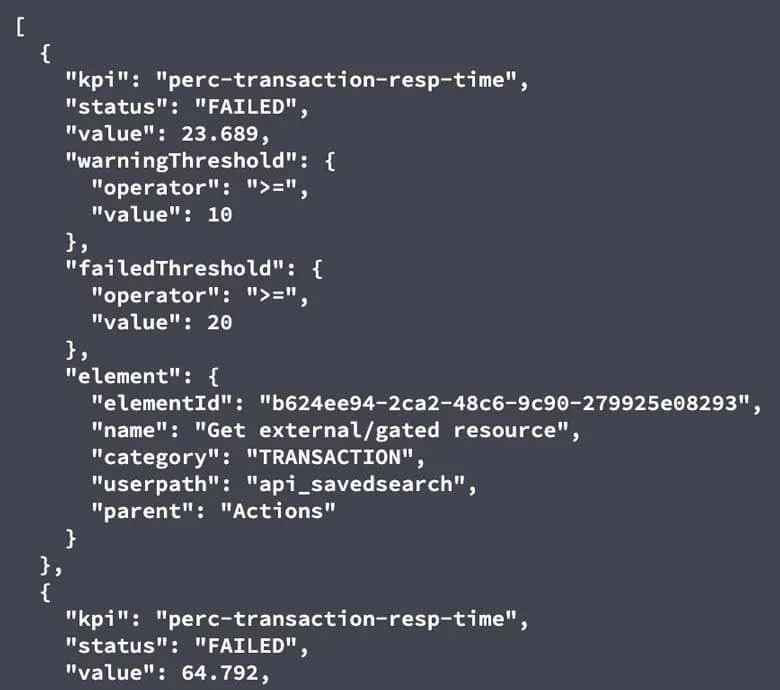
有了適當的細節級別,即使是在使用curl的簡單bash腳本中,團隊也可以快速確定導致管道無法工作的最重要因素。對這些自動化工件進行小的、可理解的更改最終將為您節省大量時間。
接下來:現代快速反饋循環,分析和趨勢
在本係列的最後一篇文章中,利用趨勢和開放API數據加速性能分析,我們看看實施持續績效實踐能給你帶來什麼。簡而言之,更好的係統,更快的故障/修複周期,更少的技術債務。
這篇文章最初是於2019年發布,最近一次更新是在2021年7月。
一定要看看我們的白皮書連續性能測試的實用指南尋求實用的建議和幫助。
日期:2021年5月11日


